
以前学习MySQL的时候,由于过于初级,学习到的都是“概念”,过于抽象,今天把了解到的Innodb对数据的存储结构做一个整理和梳理,加深自己的印象,也希望读者能有所收获。
文章围绕着 《MySQL是怎样运行的:从根儿上理解》 的部分内容展开,挑选几个关键的图表对Innodb的底层存储结构进行解释。主要包括:行结构、页结构、页的组织(B+树、索引)。
Innodb行结构——Compact型
我们平时使用关系型数据库的时候,都是一张张表,每一张表里都是自己定义的一列列的字段、一行行的记录,事实上,还有许多我们看不见的字段,而我们自定义的字段只是这一行记录的一部分内容,并且这些我们看不见的字段都具有不同的功能,它们的作用就是支撑着我们所使用的那几个字段。根据不同的使用要求,设定不同字段实现不同功能,这样的一行记录的格式,称为行格式。
这里了解一下Innodb的行格式,设计Innodb存储引擎的前辈们到目前为止设计了4种不同类型的行格式,分别是:Compact、Redundant、Dynamic 和 Compressed。以Compact为例:
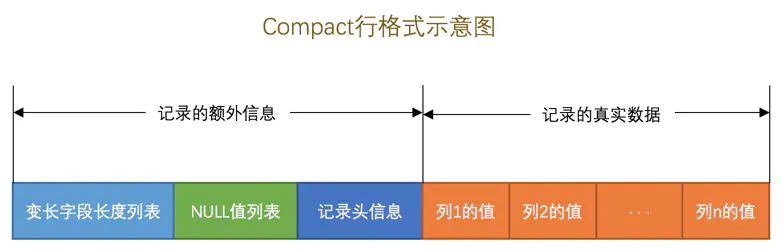
由图可以知道,Compact行格式的一行记录可以分为两个部分,分别是:记录的额外信息 和 记录的真实数据。
记录的额外信息
记录的额外信息内又可以分为:变长字段长度列表、NULL值列表 和 记录头信息。
变长字段长度列表:顾名思义,这一字段是用于记录真实数据中每个变长数据类型字段的具体的占用字节数,把所有变长字段的真实数据占用的字节长度都保存起来,从而形成一个变长字段长度列表,各变长字段数据占用的字节数按照列的顺序逆序存放(即列表跟真实数据字段呈对称形式的一一对应)。——好处:节省空间。
NULL值列表:用于统一记录真实数据字段中所有值为NULL的字段的值,只需要通过
0-不为NULL,1-为NULL即可如同变长字段长度列表一样一一对应真实数据字段中哪些字段为NULL,从而利用 bit 轻松避免了在真实数据中存储。——好处:节省空间记录头信息:用于描述记录的记录头信息,它是由固定的5个字节组成。5个字节也就是40个二进制位,不同的位代表不同的意思,如图:
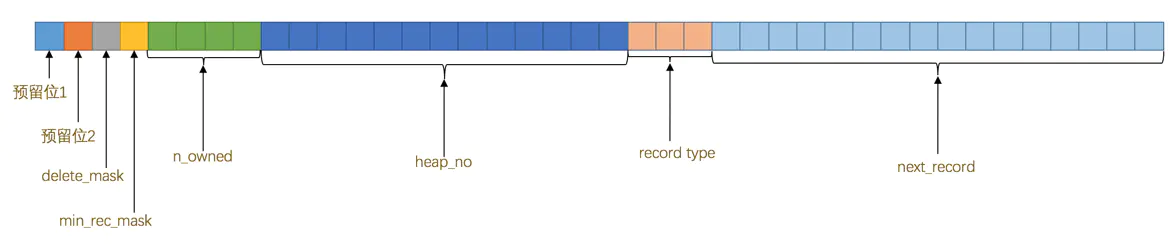
各字段介绍:
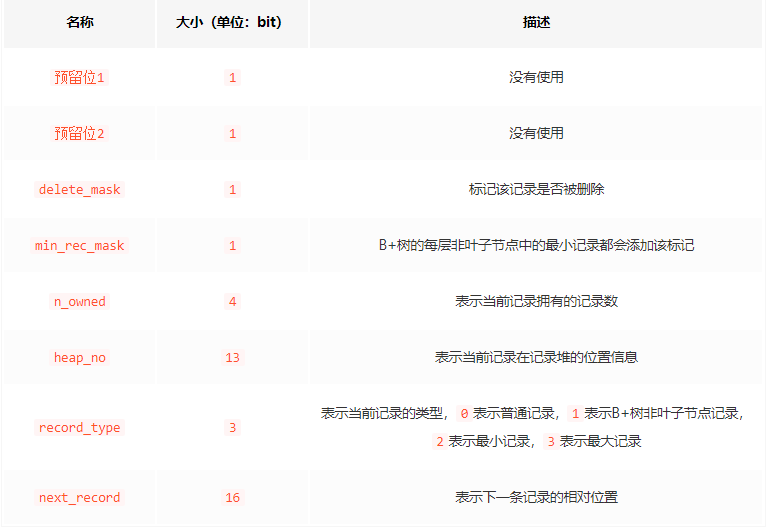
Innodb的底层结构中,最主要的就是上面的几个字段了。但是我这里为了突出底层存储结构,主要是要呈现一个数据结构。所以对一些字段并不详细介绍,有疑问或者想了解的同学的可以留言,我给你解答。
先看到next_record 字段,从上面的描述可以知道它就是指向下一条记录的开始,如下图所示,其原理就是数组下标能够直接定位到某个元素的原理。
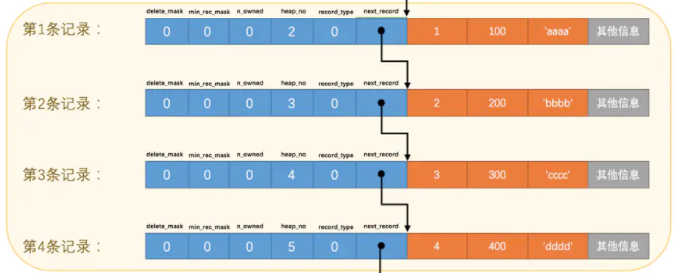
至此,我们可以看到,一个表中的数据就是一个单链表结构,每行记录通过 next_record 字段链接起来,在进行范围遍历的时候,就可以直接通过这个指针来定位到下条记录。
记录的真实数据
下面我们再来看一下记录的真实数据字段。真实数据字段也并没有我们想的那么简单,根据需要还是会增加额外的字段。
具体增加的列有:DB_ROW_ID——行id(可选)、DB_TRX_ID——事务id、DB_ROLL_PTR——回滚指针。
首先看行id,Innodb表在生成主键时,优先使用用户自定义的主键作为主键;如果用户没有定义,那么就会选择一个 Unique 键作为主键;如果唯一键也没有,Innodb就会为表创建一个默认的 DB_ROW_ID 作为隐藏主键。
然后剩余两个字段都是由Innodb自动为表添加的。从名称就可以简单地看出它们的作用,这里也不做详细介绍。
综上,我们了解了一个表中每一行数据的主要字段的作用以及行与行之间的链接关系。另外需要说明并强调的是,这个链接关系是有大小顺序的,即按照主键id的大小从小到大链接,形成一个有序的单向链表结构。如果新插入的记录的主键不是当前链表的最大值,那么它会插入到原来的单向链表的对应位置中,维持链表的单向有序。
下面,我们再来看一下Innodb的页结构。
页结构
页,是Innodb管理存储空间的基本单位,一个页的大小一般是16KB。
根据不同的使用目的,Innodb设计了许多不同类型的页,比如undo日志页、存放INODE信息的页等。这里,我们主要介绍 Innodb 的数据页结构。
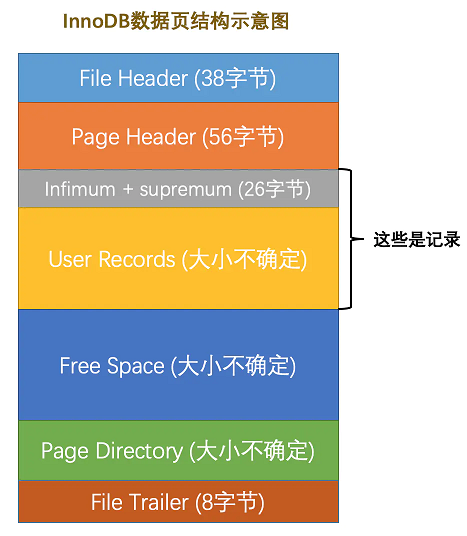
可以看到,一个16KB大小的页,被划分为了多个具有不同功能的存储段。
很明显,User Record,也就是用户记录,就是我们上面说的行记录。而它下面的 Free Space,顾名思义,是存储为空的空间,用于给用户记录分割的。也就是,我们每次插入一条记录的时候,会从 Free Space 开辟一行记录大小,并将其归并到 User Record 管理(也就是上面的next_record)。
其他模块:
File Header:文件头,用于记录页的一些通用信息;
Page Header:数据页专有的一些信息;
Infimum + Supremum:最大记录和最小记录,是两个虚拟的行记录;
Page Directory:页目录,页中某些记录的相对位置;
File Trailer:文件尾部,用于校验页是否完整。
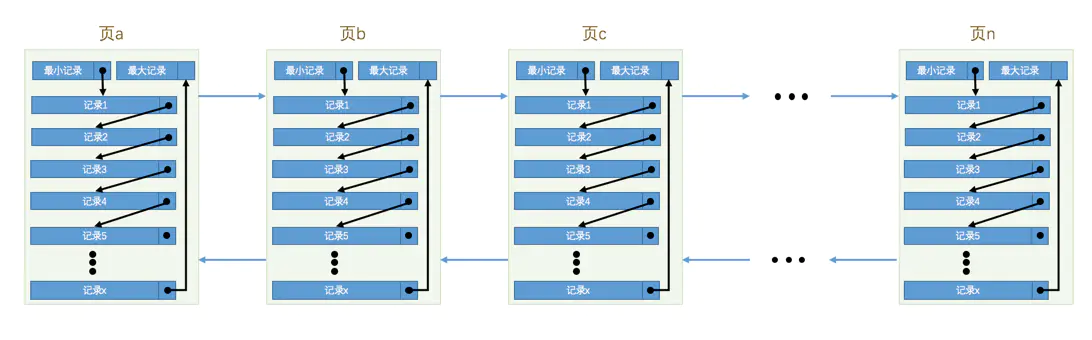
这里重点介绍File Header,文件头部。了解页与页之间的关系是怎么建立起来的。
文件头部也包含了不少字段内容,但是这里主要介绍三个:FIL_PAGE_OFFSET——页号、FIL_PAGE_PREV——上一个页的页号、FIL_PAGE_NEXT——下一个页的页号。
可以很容易的发现,这就是一个双向链表中一个节点的基本属性字段。也就是说,页与页之间,是一个双向链表的结构。
做个小结,从文章一开始,我们从平时熟悉的表字段知道实际存储的时候,Innodb还给我们增加了几个其他字段,具体增加的字段取决于我们选择的行格式,但基本大同小异。然后我们重点注意了行格式字段中的 next_record 得到行与行之间是一个链式存储结构,再结合主键的顺序也就是有序的单向链表。了解了行记录之后,我们又了解了页结构,发现,一个16KB的页划分了几个不同的功能模块,前面所有的行都是 User Record 的内容,然后重点了解了 File Header 字段,发现一个页保存了上一页的地址和下一页的地址。总的来说、宏观上来说:Innodb的页与页之间是就是一个双向链表结构,每一个页内的行与行之间就是一个单向链表结构。
B+树结构
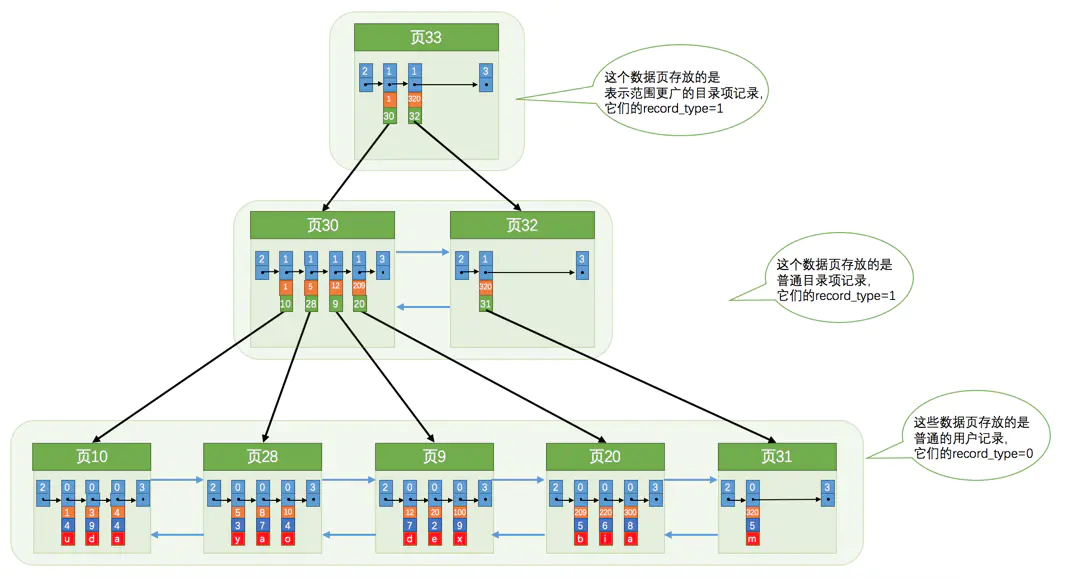
到这里,我们回头再看一下记录头信息中的 record_type,它代表的是当前记录的记录类型。记录类型一共有四种,上面说的用户的记录是 0 普通记录。这里我们要讨论的是 1 B+树非叶子节点记录。当一条记录的记录类型为B+树的非叶子结点记录时,也就是索引的记录。不会B+树的同学请Google~~~。
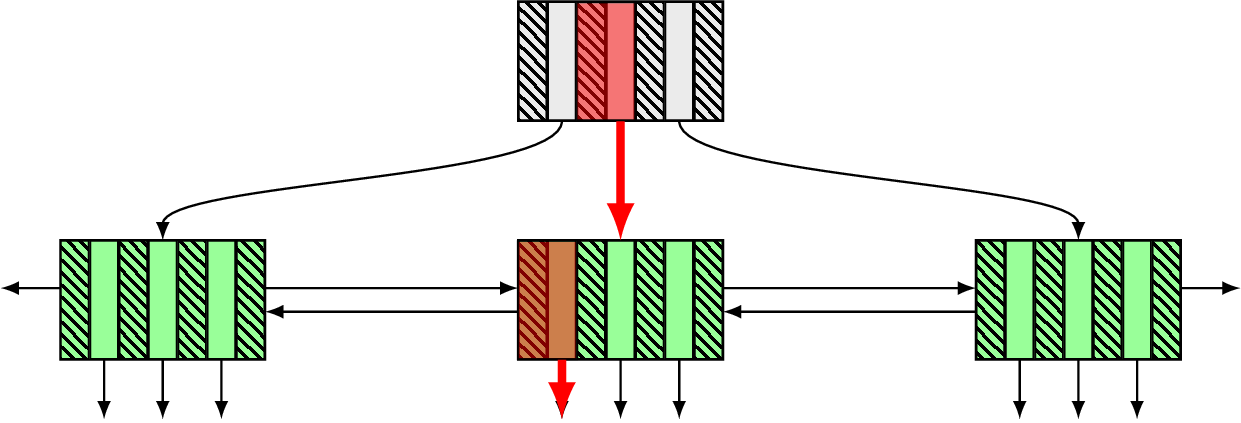
在所有的记录中,也就是上一个双向链表图结构,Innodb会选取一部分记录的主键id来组织成新的16KB特殊页,这个特殊页的User_Record 存储的就是主键id和它对应的页号。由此,我们就得到了同样的一个双向链表结构,并且每一个节点的每一条记录都映射到我们原来的所有记录中。这样,我们就可以通过得到的主键id快速定位到对应的数据页。同理,如果两层不足,那么可以根据需要继续增加。(从某个角度来说也就是跳表。 但B+树的强大使得其树高一般不超过四层)然后,我们便可以得到如下的数据结构——B+树:
总结
在本篇文章中,我们通过行结构,认识页内记录的组织,并且认识必然存在的每条记录的主键id,然后认识了指向下一行记录的 next_record 了解到每条记录就是单向链表的一个节点。认识了每个页中文件头的双向存储——上一个页、下一个页。然后我们得到了页页组织的双向链表结构、行行组织的有序单向链表结构。在此基础上,我们回头看行结构中的记录头中的 record_type,认识到还有记录类型的概念。所有值为1的为B+树的非叶子结点的记录,这些记录提取出了主键id和对应的页号组织为了新的特殊页,在这新的特殊页上就可以通过主键id快速访问到它所在的完整信息的页,这也就是一层索引,如果一层不够,我们可以在一层的基础上再抽取一层,同理可以抽取出很多层(一般四层足矣)。由此得到一个B+树的结构。
后话
文章选取了《MySQL 是怎样运行的:从根儿上理解 MySQL》的七张图片,并基本阐释了Innodb的底层存储结构,但还有许多细节我并没有详细解释,主要体现的是Innodb存储的结构。但其实每一个细节都是不应该被忽视的,它们对我们理解Innodb整一个存储结构具有非常重要的作用。
了解了实际的存储结构后,对于其他的一些概念上的东西也就迎刃而解了。什么主键索引、辅助索引、回表等就会有真正的自己的理解,而不仅仅是概念。
注:作者在书中利用了两篇很长篇幅的文章来介绍Innodb的记录结构和页结构,讲解得非常详细且无废话,给我的感觉可以用醍醐灌顶来形容。而这篇文章是我从里面提取出来的总结梳理性的文章,个人理解能力有限,欢迎勘误。另外,如果对MySQL感兴趣的话,本书值得一读,豆瓣9.4。(非广告)
参考
掘金上有电子版